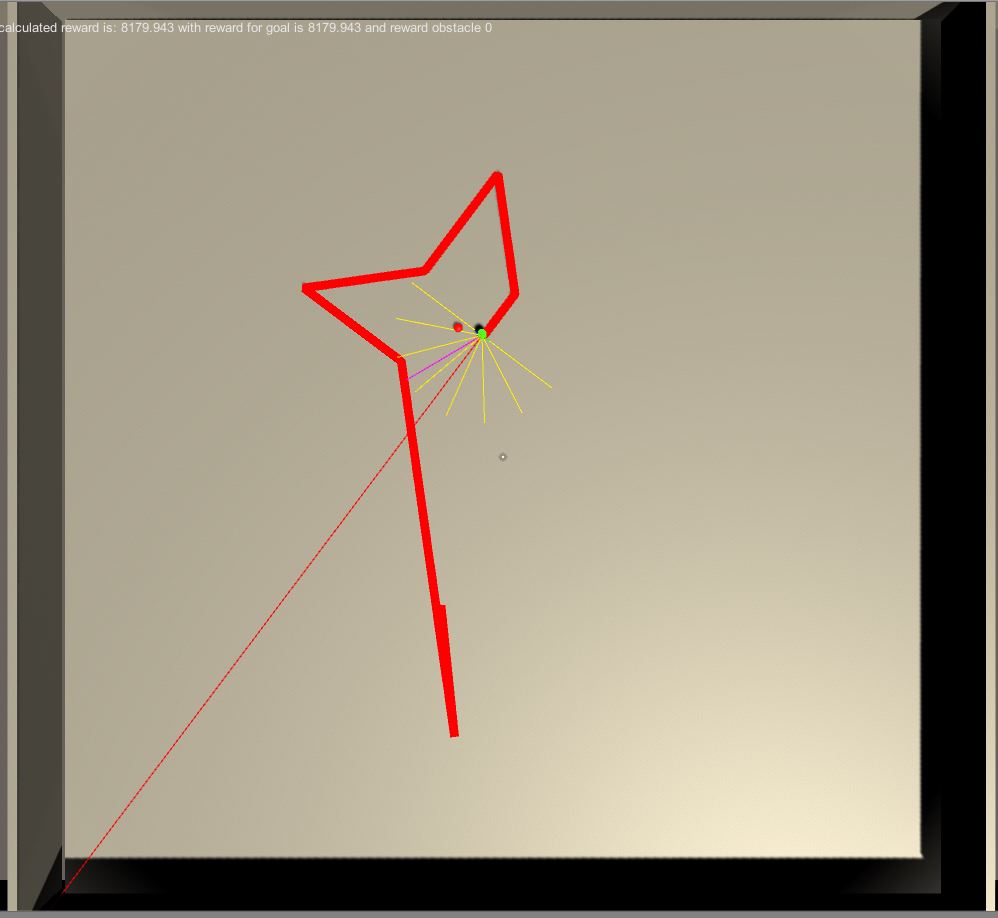
I am constantly changing the rewards and the training. Last version is, in every 1000 iteration, goal position is randomly changing.
Here is the first result
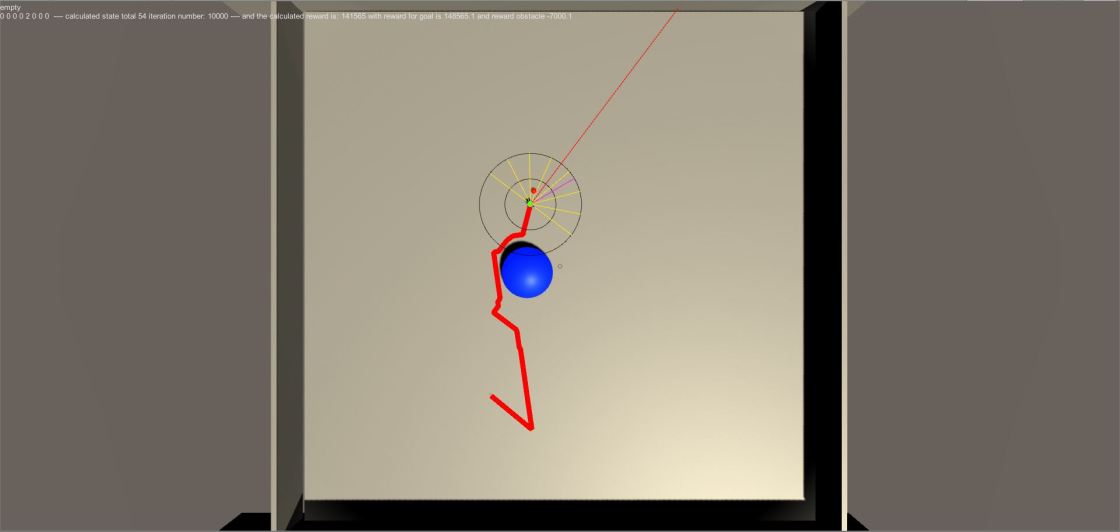
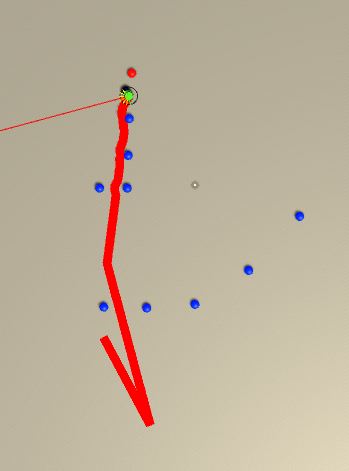
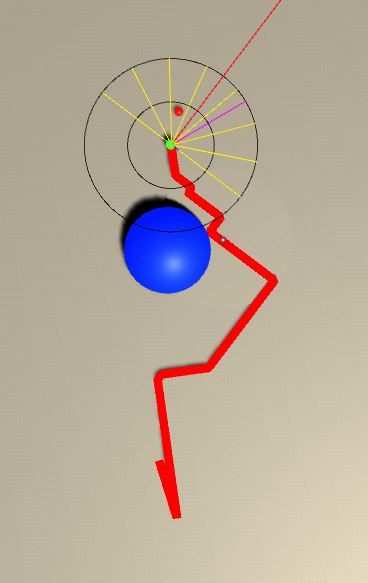
I am constantly changing the training process. Last test I did was to decrease the radius of the agent. Goal position is randomized in every 2000th iteration, and after reaching to goal, agent’s position is not changed in any way. Also, there are smaller obstacles as well. Here is the result of that iteration:
I can now make a good test now. I am giving more reward when the agent’s zero direction is empty. This is the result:
I can generate better results now. Below is the circle scenario with 6 agents. Collider radius is 0.5.
Here is another video, collider radius is 0.7 this time.
It is worth noting that with larger agents, the behavior gets stranger. Agents overlap with each other. Agents need more training maybe.
Two agent test case
RVO2 library with two agents
Here is the circle test scene. This time with 10 agents and during individual iteration, they go through each other. But with Navmesh, they do not get into each other.
Another circle test
Another test after more training. Strange results. There is something wrong with the learning process.
Time was wasting on generating tables with iterations. I am now writing the files to a text file separating the values with commas. Now I only need to run the learning process once. Then I can create agents by giving that text file as the table.
Second improvement: An error was present while selecting the maximum Q Value. I am using the standard finding maximum method. However, I was initializing the first value to 0. So when the reward is negative, it just continues with value 0. I fixed that.
After all the fixes, it is running faster and a bit better. Below are some screen shots from the algorithm. Reward for entering an obstacle is still higher.
This slideshow requires JavaScript.
I think I have good results now. I will commit this to git and start to create new actual simulations. Hopefully I will be able to conduct a user study. Seems like so but we will see.
I also need to improve the training process but now I can just add on the training files I already have.
I reached to a point where I am constantly trying the same thing and hoping it will change.
I honestly do not know where is the problem. The agent reaches to the goal. I checked the learning iteration. That is also correct. Reward logic is now fixed. I checked the state calculation a million times.
Still, the agents are not able to avoid each other when they walk towards each other in a circle. Q Learning is what the paper have used.
Rewards they have presented just do not work. Is it something else I need to do ?
I think the training is a problem with the agents. Maybe I can train in a better environment ? Right now, in each iteration there is an obstacle between agent and the goal. Do not know what else to do.
Specs for the test: Only one agent is generated. It runs for 300 000 iterations. When the agent reaches to the goal, every obstacle and the goal is moved to another random location.
Step size of learning (alpha ) is 0.1 and Discount factor (gamma) is 0.1.
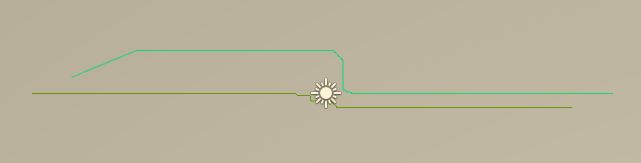
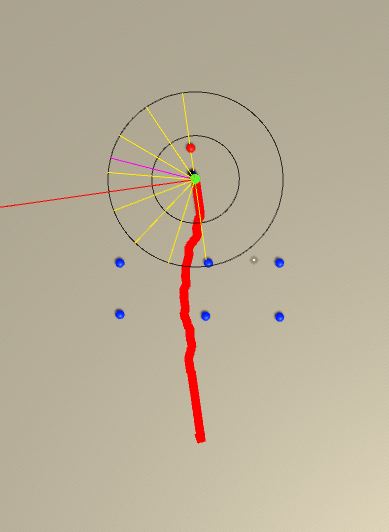
Below is the image from the sample test scene. Red circle is the goal location. Blue circle is the obstacle.
Below is a sample trajectory the agent takes while learning. Left one is after 200 000 iterations and the middle one is after 400 000 iterations. The straight line from the goal object going through the objects is the result of setting the location of the agent after it reaches to the goal. (This is while agent is learning and the goal location is not randomized) Image at the right is when there is an obstacle.
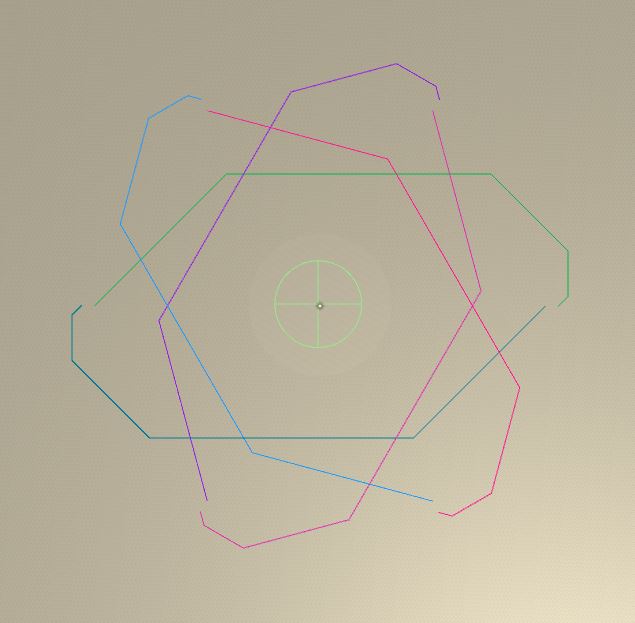
Circle scenario with the Q Learning. Behavior is very strange. Agents seem to just walk around a circle.
Simple scenario, where two agents are walking towards each other
Then here is the other version of the circle scenario.
General paths the agents follow is given in the image below:
So the way I was implementing the learning algorithm, I had two distance states and the closer the agent to an obstacle, larger the distance number was. This what is stated in the paper I am implementing.
The problem is: it does not work. When one converts the distance status into a state number, closer obstacles returns smaller numbers and therefore the agent gets closer to the obstacle. I changed my distance states. Here is an initial test.
Does not work all the time which is strange though. I will make further tests.
UPDATE: First mass crowd simulation test. Used navmesh for navigation but the logic is applicable to every strategy for navigation.
UPDATE: I created a navmesh and saved the goals of the agents in certain intervals.
and there are some pictures of the path the agent took.
This slideshow requires JavaScript.
UPDATE: So now the pedestrians have trails. Which is nice.
UPDATE: I made a test with multiple agents walking towards the same goal. Here is the initial result.
UPDATE: Here is the first attempt to run the crowd simulation. This is a video of it.
UPDATE: Here is another test case. I have decreased the radius of the agent. Now it only perceives its closest environment. Inner Radius is equal to the radius of the agent and the outer radius is the double of that value. Here is the result of that.
UPDATE: I changed the reward a bit because I am convinced that the thesis paper is just wrong. Reward calculated when there is only one object is higher when there is two objects. SO I manipulated that a bit. First result with trajectory:
—————————————————————————————————————————————–
I have begun to do the test cases specified in the thesis paper. I will update this page as I do the tests.
Here is the first result.
There is something strange about the reward calculation system. So I tried to hack it. Here is the result of that hacking:
I changed the iteration logic. Now, one iteration is now defined by agent reaching the goal. With this logic, I made 2000 iterations. The result is looking strange still.
Another test. Parameters and properties are in the description
I am convinced that there is something wrong with the reward function. This is the reason for my suspicions.
Now, it is reaching the goal but the trajectories is not nearly close to what it supposed to look like.
So I did the updates and it looks a tad bit better now. Here is the result:
Here is another test with the updated reward system.
I added trails to the agents to see how they behave. Next step is to give a very low reward when the agent goes past the obstacle. Other step is to give a very high reward when the agent reaches to goal.
Also, the scenario I set up is not similar to the scenario used in the thesis paper.